
(点击“这里”获取沈锡宁演讲完整PPT)
讲师介绍
沈锡宁,京东资深云架构师,负责京东弹性云v2.0核心架构设计工作。在通信行业工作多年,拥有丰富的通信行业软件设计及开发经验。擅长分布式系统建设、Memcached数据库、Web全栈、爬虫设计。曾多次在公司内部组织相关的技术培训(如算法、性能优化、反汇编等),项目重大问题攻关负责人。
大家好,我是来自京东南京团队的沈锡宁,很荣幸能跟大家分享京东弹性云的一些相关技术。
目前京东弹性云分为两个版本,一个是正在运营的弹性云v1.0,一个是还在研发准备今年下半年开始部署的弹性云v2.0,这两个版本的弹性云架构是完全不同的。下面先简单介绍一下弹性云v1.0。
一、弹性云v1.0

京东弹性云v1.0版本从2014年开始部署,并在下半年陆续将部分业务迁移到弹性云平台。这些业务包括商品的图片展示、订单查询等。经过两年多的运营,我们团队的技术能力也得到了业务的认可,目前京东已经将所有业务迁移到弹性云平台中,并且弹性云平台也顺利保障了本年度618大促活动。如果弹性云不稳定,故障率比较高,尤其是在节假日或者大促活动中出现故障的话,那就不是几个订单的问题了,不出意料,老板就要发飙了。
目前我们生产环境中的容器数量已超过15万,我不知道这个规模是不是全球最大的,但能肯定的是,这应该是国内容器规模最大的。
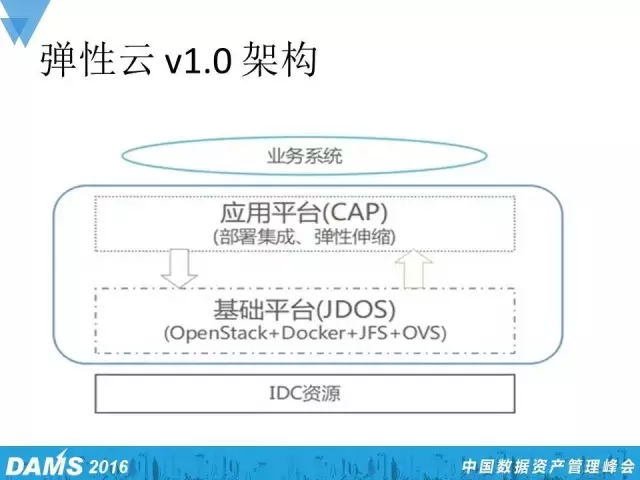
先给大家介绍目前正在运营的弹性云v1.0的架构。在架构图最底层是IDC资源,IDC资源作为京东的物理资源,遍及全国三地,分别是华东、华南、华北。在物理资源之上,是我们的技术平台JDOS,通过OpenStack+Docker来构建。这里可能有的同学就有疑问了,使用OpenStack组建私有云平台,那如何让你的云计算变得有弹性起来呢?或者说让业务进行弹性伸缩呢?对此,我们通过自研的一套应用平台,简称CAP,来负责治理应用、部署集成、监控以及业务手动的、自动的弹性伸缩。
打个比方,京东的大部分业务都提供外部服务,平时可能某个外部应用只需要启动几十个容器的集成就可以满足外部的访问需求,但到了节假日,尤其是促销活动的时候,这点规模是完全无法满足外部巨大的访问流量。因此,我们通过应用平台CAP使得业务可以手动或者自动地对外部集群进行扩容,和日常的缩容。
也有朋友可能会问,对国内外做云计算、做私有云产品、做云平台的公司来说,他们都喜欢采用OpenStack+KVM的方式来构建计算平台,京东为什么要采用OpenStack+Docker这种方式呢?我们是有考量的。
我们发现使用OpenStack+KVM这种方式构建京东弹性云平台的话,在构建某些场景虚拟机的物理计算性能时会达不到业务所需要的性能,如果强推这种方案,可能会给我们的RDZ资源带来额外的压力。
下面验证一下使用Docker虚拟机引擎。我们发现,使用Docker作为虚拟机引擎,物理计算性能和内存性能是完全可以媲美物理机的。除此之外,用过Docker的人都比较了解它的特点,Docker具有轻量、便捷等优点,所以最终我们决定使用OpenStack+Docker这种方式来构建弹性云平台。
基础平台中还有个JFS,这是我们自研的一套分布式文件系统,用于弹性云平台的存储。OVS,虚拟化交换机,我们通过OpenStack Neutron+OVS来构建弹性云的网络。
那么,我们是如何用OpenStack+Docker来集成的呢?众所周知,OpenStack支持包括KVM、qemu、Docker和其他多种虚拟机引擎,如图所见,我们采用的是Docker虚拟机引擎,通过修改Nova这个计算节点的配置文件,将其虚拟机引擎改为Docker引擎。
如果一个外部用户申请创建一台虚拟机或者启动一个虚拟机实例,那么他首先需要通过Keystone的认证,Keystone组件的认证主要负责认证用户的合法性,是否有权限创建一台虚拟机或者启动虚拟机实例。通过Keystone的认证后, Nova scheduler这个模块会在所有的物理计算资源中找一台合适的物理机去启动或者创建符合用户规格要求的虚拟机实例。
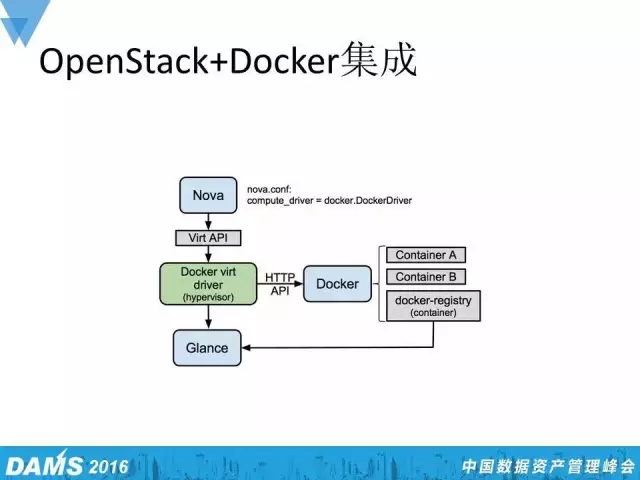
这幅图中,假设在Nova这个计算节点接收到这么一个创建虚拟机的请求,那接下来它就会调用Docker虚拟机引擎来创建一个虚拟机容器,容器在这个过程中会向Glance组件要它的镜像系统,获取完镜像系统后容器实例就能很快地启用起来。
京东的容器实例在运行完上述讲到的流程之后,还会向我们自研的一套配置系统要这个容器的配置数据,获取到配置数据后,容器可以根据配置数据的信息来决定这个容器实例是否要加入到某个业务的集群当中,如果这个业务容器是对外部的应用,那它还有可能会根据配置数据去获取外部前段、后端的代码。
弹性云v1.0的网络,使用OpenStack Neutron+OVS的方式构建。我们通过OVS VLAN,做到了网络隔离。接下来用一张图讲一下弹性云网络中的VLAN内数据收发和跨VLAN的数据收发流程。
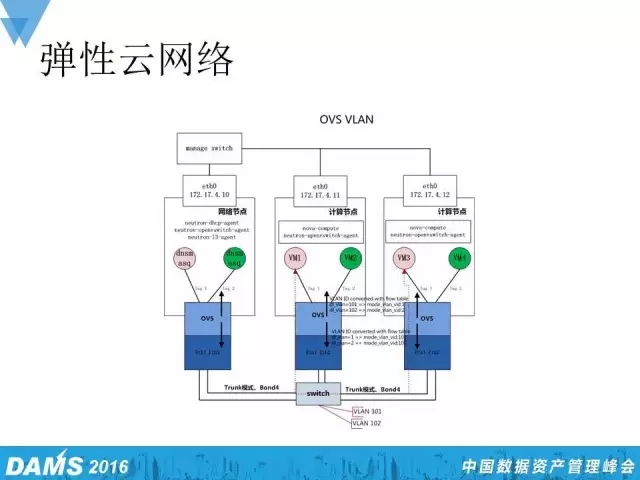
如图,有一个网络节点和两个计算节点,每个计算节点有两台虚拟机。其中,粉色的虚拟机VM1和VM3是属于同一个VLAN,绿色的虚拟机VM2和VM4则是属于同一个VLAN。那么,如果虚拟机VM1有数据要外发到虚拟机VM3,它的流程是怎样的呢?通过OVS。
首先,根据外发数据包的目的地址和它虚拟的VLAN ID,在6秒内进行转换,找到它的真实VLAN ID。如果发现目的地真实的VLAN ID跟自己的VLAN ID是相同的,那么OVS就会把这个数据包交给最底下的物理交换机。物理交换机收到这么一个包后,它首先会在自己的ARP表里去找有没有这个数据包Mac地址记录,如果有的话,物理交换机就会直接把数据包转发给虚拟机VM3;如果没有的话,物理交换机就会把这个网络数据包在网络上进行广播,每个计算节点收到这个广播包后都会看这个包里的目的地址VLAN和我旗下的VLAN匹不匹配,右侧的计算节点收到这样的数据包一看,虚拟机VM3的Mac地址和目的地的Mac地址是一样的,那么它就会把这个数据包转发到虚拟机VM3。这是VLAN 内数据收发流程。
接下来的数据收发流程又是怎样的呢?如果VM1有数据要发到VM4,假设首先OVS先收到这样的数据包,然后通过流表发现,目的地真实的VLAN ID和原地址的VLAN ID是不同的,那它就会把数据包交给网关,也就是交给我们的网络节点。网络节点上有个虚拟的路由器,虚拟路由器通过自己的虚拟路由把数据包转发给VM4的VLAN ID的网络。VM4的VLAN ID的网络收到这样的数据包后,再通过OVS把数据包转发给VM4。这是一个跨VALN的数据收发流程。
刚才讲了弹性云v1.0版本的架构、网络和集成,再给大家讲一下运维系统。我们的运维系统JDOS(也就是之前讲到的基础平台),这个基础平台负责物理资源、网络资源、存储资源、容器生命周期以及状态监控等管理。
跟大多数的云计算平台界面差不多,先选取业务小运行的镜像系统,然后选取规格、网络、主机名以及一些想要的容器数量,提交完这一切之后,只需短短几秒钟的时间,虚拟机实例便启动完毕了。最后通过暴露的内网IP就可以登录到这个机器上做相应的后续操作。这就是用Docker作为虚拟机引擎的优势。相信大家都用过公有云的产品,我们在某个公有云的厂商创建一台虚拟机,常常会发现其中一个虚拟机实例创建完后可能需要等待一分钟的时间,而JDOS仅需要几秒钟就启动完毕了。
应用上线系统
再看到应用上线系统。京东所有新的业务假如要部署在弹性云平台上,都需要通过我们自研的这套应用上线系统进行申请。这套应用会告诉我们想要的容器实例的镜像系统规格是多少,想要部署在哪个机房,数量是多少,这一切提交完毕,如果审核通过,我们就会给它部署相应数量、规格的虚拟机实例。这是应用上线系统。在左侧菜单还有个扩容的功能,业务可以通过扩容功能对现有的容器集群进行扩容。
运维控制台
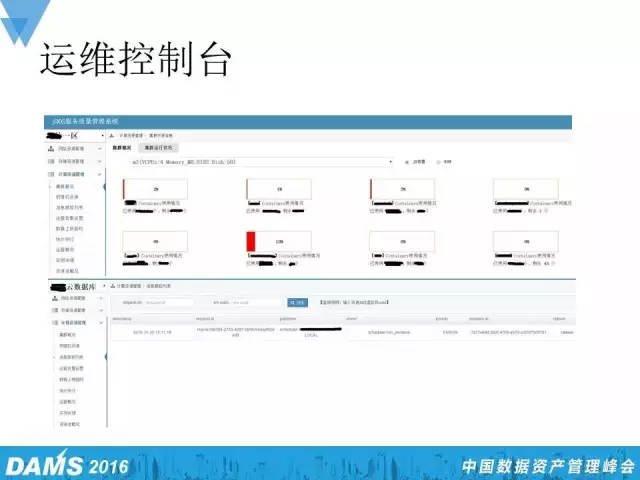
除此之外,我们还有个运维控制台。这是我们自研的一套集监控、物理、虚拟机、存储及网络资源的系统,通过上层可以选取京东的一些数据区,根据规格来检查规格下面所有的容器实例数量及状态,看这些容器是否有异常。下层可通过消息跟踪列表输入消息ID,来查询消息的执行状态。所有监控的功能都是通过OpenStack的restful api方式来获取相关的状态信息。熟悉OpenStack的人可能会用另外一种方法,就是Nova这种计算节点和cinder这种存储节点都有自己的一套MySQL数据库,用于存储各个资源的信息,实时地维护。因此熟悉OpenStack的人可以自己设计一套运维系统,即直接通过SQL的方式来获取一些想要的资源的状态信息,这样做的一个好处就是可以绕过获取权限、令牌等这一步。
其他运维工具
除了前面谈到的几个自研的运维工具之外,我们还研发了其他的运维工具。比如说消息追踪,我们会把RDZ相应的消息注入到database里,对网络状态进行监控,对内核的相应信息进行追踪。
另外,我们还自研了一套自动化的巡检系统。这个巡检系统会每天定时扫描每个数据中心下的物理机资源、虚拟机资源、存储资源、网络资源的状态信息,并把这些信息汇总,以邮件的形式发送给运维人员。运维人员收到这样的邮件后会去看有没有容器实例出现异常、哪个机房出现了告警,如果发现异常就会去做后续的故障定位。这个巡检系统极大地降低了运维人员的人力成本,因为目前京东弹性云的版本是超过了15万个用例,如果用纯人力来巡检这么多的容器实例,工作量是难以想象的。
我们的OpenStack是使用Docker作为虚拟机引擎来构建弹性云平台,那京东对Docker都有哪些设置呢?

首先是从cgroup。cgroup的意思就是对容器进行资源的控制和隔离。我们在cgroup里面进行了cpu set和cpu share。cpu set就是对容器运行的实例进行饱和操作,让容器的实例可以运行在某个或某几个cpu核上。cpu share就是控制容器的cpu资源比,如果我们不设置cpu set的话,容器实例就会采用物理计算资源默认的cpu调度策略,使得有时候容器可能会运行在这个核上,有时候会运行其他的核上,这种方法很难让我们良好地监控和管理容器实例。如果不设置cpu set的话,容器的性能也有可能会达不到业务所要求的规格性能。我们对容器实例所运行的cpu调度算法,采用的是cfs绝对公平的调度算法,保证容器实例各个进程的虚拟运行时间相对公平一些。除了cfs这个算法之外,cpu还有其他两种调度算法,分别是fifo,rr,这两种算法对实时性要求比较高,我们没有对实时性要求比较好的应用,所以采用的是cpu默认的调度算法。
对于存储,我们采取的是cfq,也是一种绝对公平的队列算法。这里有个deadline算法我们没有采用,deadline调度算法可能对数据库应用显得会友好一些。除此之外,我们禁用了Dokcer的网络,熟悉Docker的朋友可能知道,Docker也有自己的网络。Docker其中的容器实例如果想要外发数据包的时候,会通过桥接的形式,把数据包通过物理机的某个网口转发出去。Docker网络有它的劣势,它不能够跨物理机共享同一个子网,直到Docker的1.9版本才终于支撑OVS这种方式。我们因为使用Docker比较早,所以禁用Docker的这种模式,而采用OpenStack Neutron,即OVS来构建我们弹性云平台的网络,让容器实例可以跨物理机间共享同一个子网,容器实例能够在不同子网之间互相访问。
我们也加强了监控,对于进程的信息和进程打开的文件句柄数量都进行了监控。我们还研发了一个小的工具——镜像build。这个工具能够根据业务的规格需求和镜像的操作系统需求快速地构建一个业务所需要的镜像。
二、弹性v2.0

采用Kubernetes组建京东新的弹性云平台
弹性v2.0是我们今年正在研发,准备下半年部署的一个系统,下半年可能也会将京东的部分业务迁移到这个平台上。这个平台跟v1.0的架构完全不同,为什么这么说呢?因为我们采用了Kubernetes组建京东新的弹性云。Kubernetes是Google公司开源的一套容器管理平台,由公有云开发,绰号是k8s。k8s的由来大概是因为社区里的某个人觉得Kubernetes这个单词念起来比较拗口,就把这个单词拆分了一下,去除一头一尾k和s,中间还剩下8个字母,所以就把Kubernetes称之为k8s。后面我也会用k8s来代替Kubernetes。
抛弃CAP弹性伸缩模式
之前讲到v1.0版本有个CAP应用平台,这个平台主要实现了我们弹性云v1.0的弹性伸缩,在v2.0中我们抛弃了CAP弹性伸缩模式,改用Kubernetes容器管理平台中的Replication Controller来实现新一代的弹性伸缩。
组建新一代的日志收集、分析以及查询
除此之外,我们还构建了新一代的日志收集系统。经过两年多v1.0平台的运营,我们发现,在大部分容器和物理机出现异常时,都需要运维人员登录到相应的机器(虚拟机/物理机)上去看,检查日志,可能还需要传输日志,如果日志文件非常大,在传输文件的过程中会占用一定的I/O资源和带宽资源,这是一种备用的日志收集方式,也就是等出了问题再上去看,而且比较占用资源。在v2.0中我们化被动为主动,使用ELK来组建一个新的日志系统,主动地去收集日志、分析及查询。
在介绍弹性云v2.0平台的架构之前,给大家讲一下k8s的相关术语。

Master Node
Work Node
大家看到Master Node和Work Node都包含node这个词,可以简单地把node视为一个物理计算资源,或者把它看做一台物理机或者虚拟机,能够提供计算资源。所以,Master Node是指容器管理平台,类似于OpenStack的管理节点,通过Master Node可以创建k8s所有的逻辑对象,比如说Pod,Replication Controller,Service,Namespace等。而Work Node则相当于OpenStack中的Nova节点,用来部署容器实例。
Pod
Pod,指一组容器或者一组协同工作的容器,它是k8s最基本的一个操作代源,什么都离不开Pod。可以视一个Pod为一个应用。有时候我们可能会创建一个Pod,这个Pod里面只起一个容器,这个容器是外部服务,即一个Pod对一个容器。我们也可以启用一个Pod,这个Pod里启动了两个容器,一个容器专门运行外部服务,一个容器构建数据库应用,对外部服务进行服务。这两个容器构成一个Pod,提供了一整套的外部应用。
Replication Controller
这个是k8s最显著的一个特性,通过它来构建v2.0的弹性计算和业务的弹性伸缩,保证一组相同的Pod能够同时正常地工作。比如说我用Replication Controller创建了5个Pod,但这5个Pod中有一个可能因为处理巨大的外部访问流量,或者因为软件Bug,它停止工作了。这时Replication Controller就会启用一个新的Pod,来代替停止工作的Pod,让这一组Pod在任何时间段都维持5个数量的正常工作。我们可以利用这个特性来构建真正的弹性云伸缩。为什么说是真正的呢?比如说,我们可以监控网络流量,当发现网络流量在平滑递增,这时就可以通知Replication Controller在这组Pod集群里扩容,反之,当网络流量递减时,可以通知Replication Controller进行缩容,但不管是缩容还是扩容,它都不会停止Pod的业务。
Service
Service,指一个Pod所能对外提供的服务。通过Service,当我们有一组Replication Controller创建的Pod想要对外提供服务,就可以通过创建一个Service对外暴露一个IP地址和端口,让外部的流量通过Service来访问Pod或者一组Pod。Service还有一个特点就是,它可以充当一组Pod的负载均衡,假如你用Replication Controller创建了一组相同应用的Pod,通过为这组Pod创建一个Service,使它拥有一个对外的服务入口,当外部的应用、访问流量通过Service访问Pod所提供的服务时,Service会把这些访问请求均匀地配给每一个Pod容器,相当于这组Pod私有的一个负载均衡。
Namespace
Namespace,是指它能够帮助不同的项目和团队共享一个Pod集群,或者防止不同团队之间命名冲突。
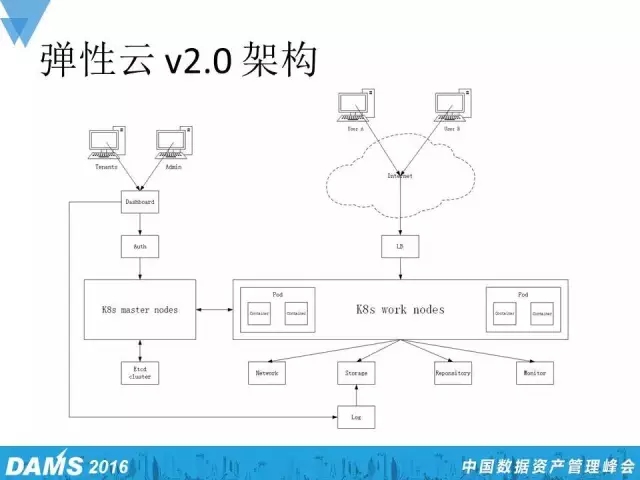
这是弹性云v2.0平台的架构。平台通过Dashboard对外提供UI服务,通过认证的组件提供认证的相关功能,用Master Node来提供管理容器平台相关的功能。 Master Node下面有个Etcd cluster,这个集群是用来作为存储, Work Node上面的Pod、Service、Namespace、Replication Controller所有这些配置信息都存储在这个Etcd集群当中。Work Node下面挂着几个组件,分别是网络组件、存储、镜像中心和监控。弹性云v2.0的网络还是会采用原先的OVS来构建,并且这个网络会让每个Pod跨物理机间能够互联互通,Service能够被外网所访问。存储Storage下面是一个Log,即我们新一代的日志系统,然后Repository是镜像中心,监控Monitor我们会用社区的heapster来构建物理机和容器监控状态的一些应用。

下面给大家介绍一下Etcd的集群。Etcd是用于服务发现、配置存储的一套Key/Value键值系统,它通过Raft的算法来保证数据的一致性,通过自己的选举算法来保证集群节点的高可用性。打个比方,这个集群有5个节点,一个Leader节点和其他4个Follow节点,当Leader节点挂了、宕机了,Follow节点就会从其他4个节点中重新选取一个Leader节点,充当完Leader节点后所有正在运行的集群节点的版本号就会更新,而当原先宕机的Leader节点恢复正常工作后,它们会比较两个集群之间的版本号,如果发现版本号不一致,会把原先Leader的角色更改为Follow的角色,加入到集群当中。
Etcd集群中有三种模式,分别为静态模式、Etcd Discovery模式、DNS Discovery模式。简单介绍这三种模式的优缺点。
静态模式
静态模式的优点就是部署非常快速,只要知道这几个集群、物理机之间的IP地址,就可以迅速地把集群搭建起来,它的缺点就是伸缩性不强,当你发现随着业务的增长,Etcd的集群不够用了,这时如果你要进行扩容,就必须把你的Etcd集群停止掉。
Etcd Discovery模式
Etcd Discovery模式的优点就是便于测试,可以把你的Etcd集群的配置信息直接委托在Etcd的官网。缺点也很明显,你需要外网环境,需要信任Etcd的官网。还有一种情况就是你没有外网环境,也不想把你的Etcd集群信息暴露给官网,那你就需要准备另外一套Etcd集群来保存你新的Etcd集群数据。
DNS Discovery模式
DNS Discovery模式的优点是可以通过DNS主备服务器的方式来实现对Etcd集群的平滑扩容,缺点就是这个配置太复杂了,要专业的运维人员去对DNS服务器配置相关的SRV记录,这个SRV记录有一定的格式,有好几个字段。如果有一个字段或者一个字母写错了,DNS服务器就起不来了。
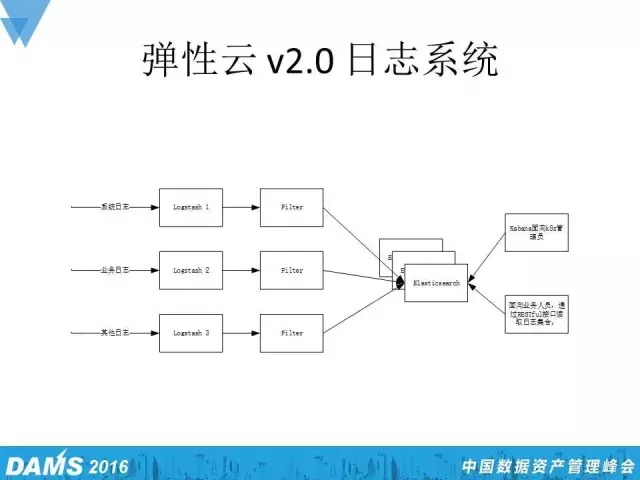
最后给大家介绍弹性云v2.0的日志系统。我们用了Logstash和Elasticsearch来构建新一代的日志系统,其中Logstash承担主动收集日志的角色,它会不断地去侦测存储设备里的日志信息,找到了之后会把这若干条新的日志格式化,转化成能够接收的格式,并传输到Elasticsearch集群当中。Elasticsearch收到这样的数据后,会把这些数据根据日期、日志类型存储为文件并创建索引,再把存储的文件和索引拷贝,分别复制到集群的其他节点当中。这样,即使有一台Elasticsearch节点宕机了,也不会影响到日志的正常收集和对外查询。
通过Elasticsearch所提供的restful搜索日志的方式,我们不仅给运维人员提供了命令行形式的日志搜索,也可以在Dashboard中集存一些功能,也就是提供一些图形化的日志查询功能。



扫码关注
获取峰会最新信息