
刘伟光丨Pivotal公司大中华区总经理
EMC公司是全球存储市场的领导者,VMware是全球虚拟化领导者,2013年这两家公司把一部分软件资产剥离出来进行重组,成立了一家新的公司——Pivatol。很多人认为这是一个比较生僻的英文单词,它的意思是“极其重要”。我们要扮演积极重要的推动者,末来将打造成面向企业级数据的PaaS平台。未来,数据与云两者的联系将越来越紧密,这已是一个重要的行业趋势。在互联网时代,软件有很多新的玩法,开源将成为末来市场很重要的生命活力。Pivatol正是秉承着将开源和企业版相结合,为企业级客户提供更完整更多选择的硬件和软件的解决方案。

根据多年的实践和经验,谈一谈我们对大数据的理解。左边是从百度上搜索到的所有关于大数据的信息,右边是我们在实践中的理解——单纯的数据与平台没有意义,只有当相关的数据结合到客户需求以及企业业务目标的模型并通过极致友好的应用渠道让用户真正受益,这才是大数据技术的意义所在。这里面有几个关键的信息跟大家分享一下:
很多人把大数据时代的数据模型设计跟传统数据仓库时代的有一个概念的混淆,大数据时代意味着很多无序和杂乱的数据,这些数据关联起来使得我们用传统方法很难做分析和模型设计,这是大数据在中国市场为什么很难焕发生命力的重要瓶颈。第二点,很多人谈大数据必谈Hadoop,或者谈MPP必谈Hadoop,但是在今天,没有一种技术能够涵盖大数据的全部内容。举个例子,当我们从上海到北京,会收到一条“欢迎来到上海”的短信,这是一种典型的信令。信令分析当中数据来自交互设备,这些数据的存储,有结构化数据,非结构化数据,级别在PB以上。同时,在特定场合下,需要进行快速的分析和推送。这既有对数据库级别的要求,又有对存储管理大的要求,同时还要对低架构Hadoop的管理,还要在特定时期对高速实时内存的快速营销。讲这么多,没有哪一种技术能满足全部要求。所以,我们应该通过业务模型去推导出合理的技术,形成相对混合的架构来通过商业价值分析匹配不同的数据技术,搭建属于企业的整个大数据或数据管理的设置。
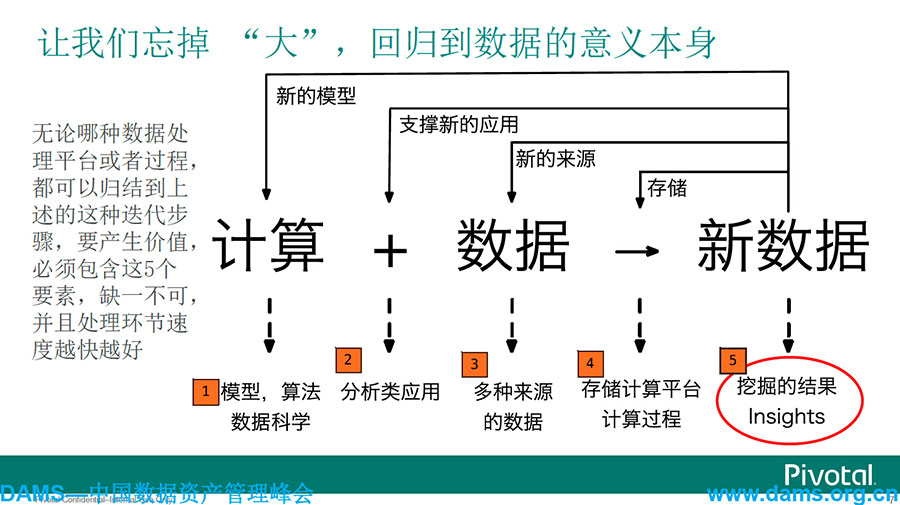
以上是一个传统数据的处理方式,是一个典型的流程。以下是我们经过实践经验对大数据得出的新总结。
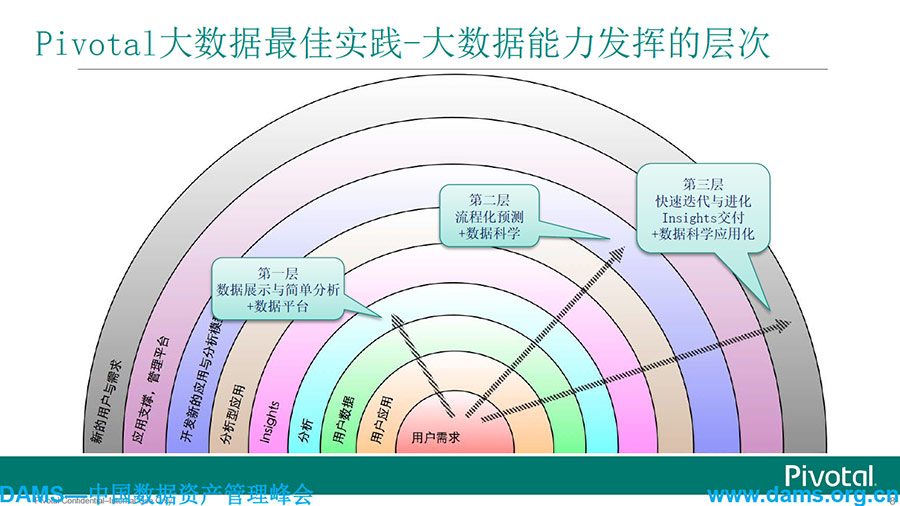
在这里给大家讲一个干货 ,我们做了一个中国最大家电公司的大数据平台调查,它的数据除了传统的数据仓库和拓扑之外,它需要在它所有跟它有关的网站,尤其新浪微博和各个论坛上,驱动爬虫技术抓取所有它的彩电、冰箱、空调的客户反馈,来进行产品定位和产品分析等更深层次的挖掘,用数据来甄别产品的问题在哪里。这个技术发展非常难,因为每天数据量非常大,无法通过传统数据库获取。要应对这种存储和技术的要求,就要对数据库和Hadoop进行整合。
第二个案例,台湾有一家做广场大屏幕液晶显示屏的公司,每一个晶片的灰度有13个等级,如果等级到5以上的话,产品就能赚钱,少于5个等级就亏钱,所以公司必须要求灰度达到10以上。但实际上从肉眼看,等级1到13是看不出区别的。说了这么多,这跟大数据有什么关系了?每一个晶片的生产过程中,电流、电压、传感器这些数据全是机器读出来的,每天产出的数据量非常大,都是上PB级别的。有这么多数据,在最困难的时候找不到这些数据的关联,这些数据怎么组合才能使灰度达到13呢?第二个困难,生产环节有90个步骤,当做到第10个步骤的时候如果没办法发现次品问题,这种不可避免的财务浪费就会产生。因此,如果能用新的数据模型来处理上述问题,他们愿意掏更多钱来搭建大数据平台。后来我们派了专家在那里工作了4个月,重新设计数据模型和算法,最后达到在第4个步骤就能检测到次品问题。

大数据不仅用于互联网,更应为各行各业所用,才能发挥出大数据的价值,使传统企业焕发出新的生命力。所以,我们认为,APPS、DATA、ANALYTICS三位一体的数据智能才能真正发挥大数据的威力。
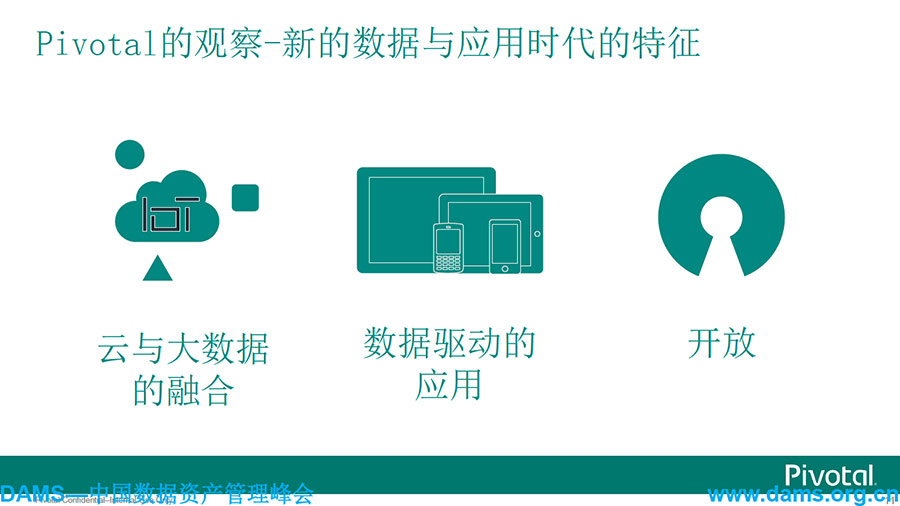
云和大数据的融合是一个必然的趋势,亚马逊、阿里巴巴未来都会对他们的云平台与大数据做一个更深入地结合;而数据驱动业务也将是未来一个重要趋势,一些做得很好的手机APP,无疑不是后台数据起到了支撑和驱动的作用,如大众点评,淘宝等,如果没有数据支撑,估计就没人会用到这些东西;开放式平台也将是未来必然的趋势,一种是硬件开放式平台,用X86技术来搭建替代原有的重量级架构。另一种,用开源技术和商业化集成技术来搭建企业级支撑平台。

我们把这个话题更细化一点,开放能避免技术锁定、依赖生态环境、共同创新;敏捷能缩短创新周期、降低TCO、加速Time To Market;云亲和能专注解决业务问题、避免IaaS锁定、确保安全性。

以上,是我们Pivotal基于新的互联网时代准则提供的组合产品。
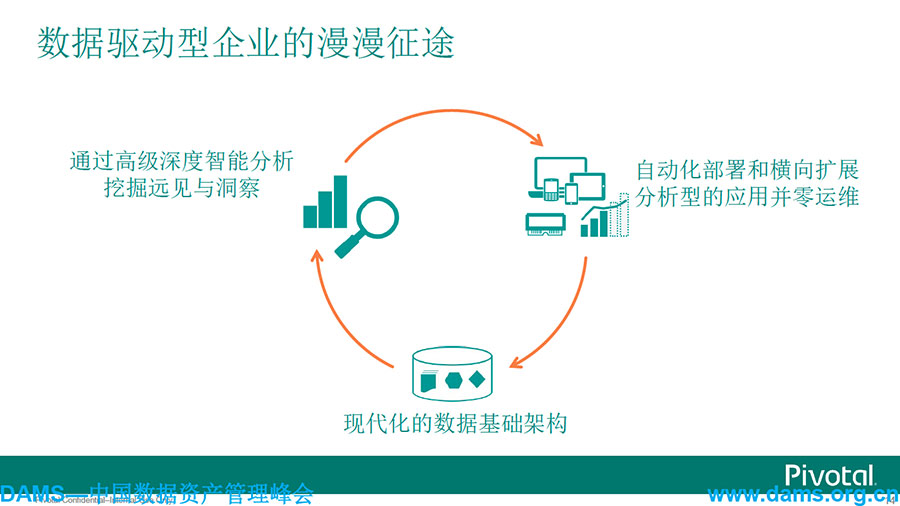
我们来看下,今天我们在做的案例中,发现的问题如何以上这些来帮助企业实现数据调整。今天大家所看到的,无论是政府、金融、税务、教育、电信等无疑都用到了大数据,这些数据和移动互联网的发展推动了行业的趋势——数据驱动应用。通过高级深度智能分析挖掘远见与洞察,通过现代化的数据基础架构能够满足所有数据源的管理和存储,通过自动化部署和横向扩展分析型的应用并零运维,实现云平台整体的整合。
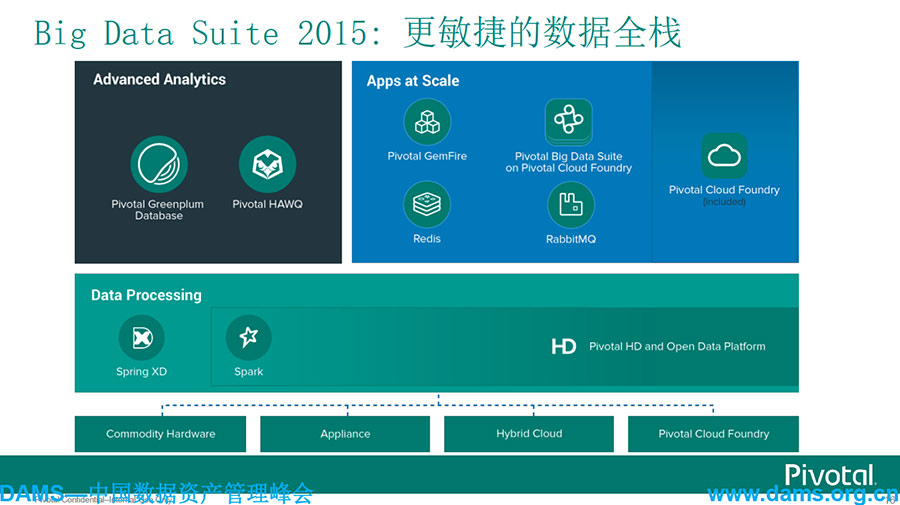
我们推出了一个新组合叫BDS,除了采用Greenplum数据库、Hawq、Gemfire之外,还采用了Spring XD和Spark。Spark不属于Pivotal,但我们对这种开源技术做了一个深刻的整合,将我们的产品与它做了无缝的集合,使Spark技术与这个套件中的其他技术实现非常好的整合。同时,我们还把开源产品Redis和RabbitMQ放在当中,给客户实现了多个选择。
以上我们一个整体分析的架构图,在不同层面如何帮助客户解决不同的问题。

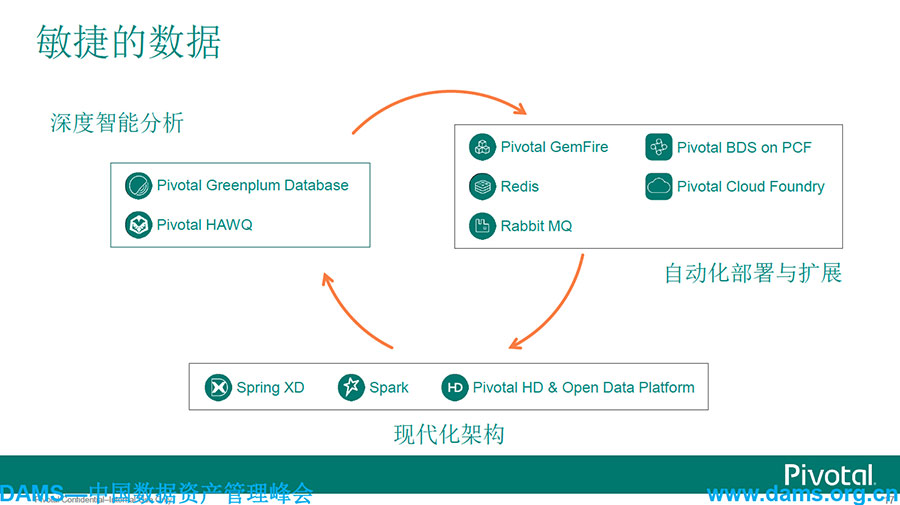
这里进一步细化,从数据工程管理,科学计算到我们敏捷开发层面,我们在每个层面上,无论是我们公司自己的产品,还是跟Spark这种开源技术的结合,都形成了开源加商业化运作。放眼全世界,目前只有Pivatol将自己产品和开源产品进行组合优化。
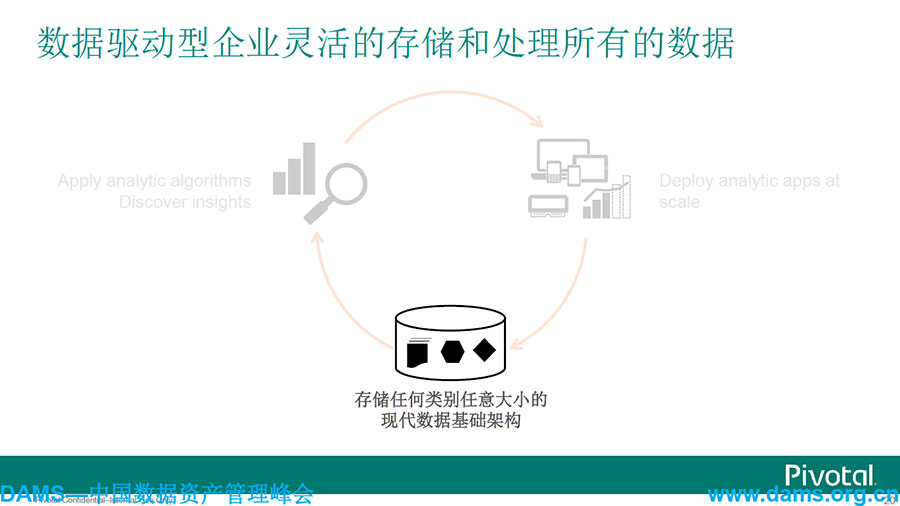

数据驱动型企业灵活的储存和处理,应该是能存储任何类别任意大小的现代数据基础架构。无论从Hadoop、Spark,还是从Spring XD能够去满足企业各种各样数据源的管理。
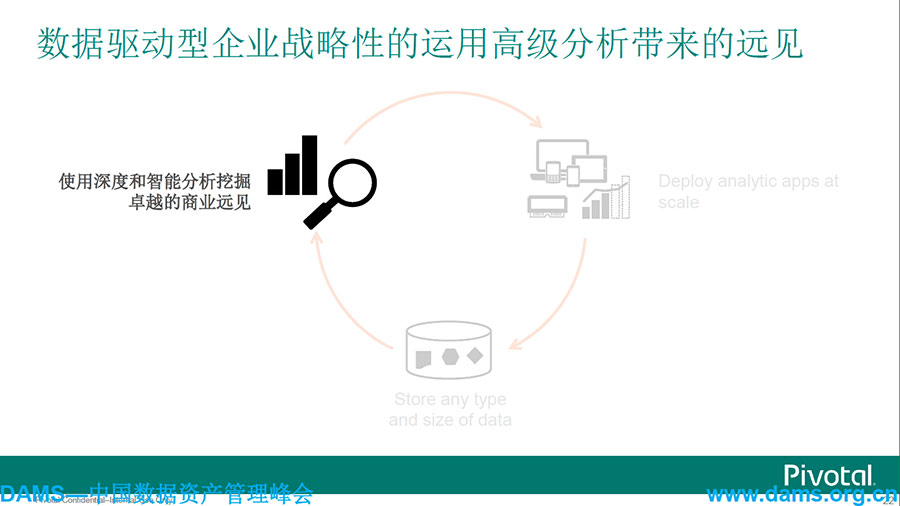
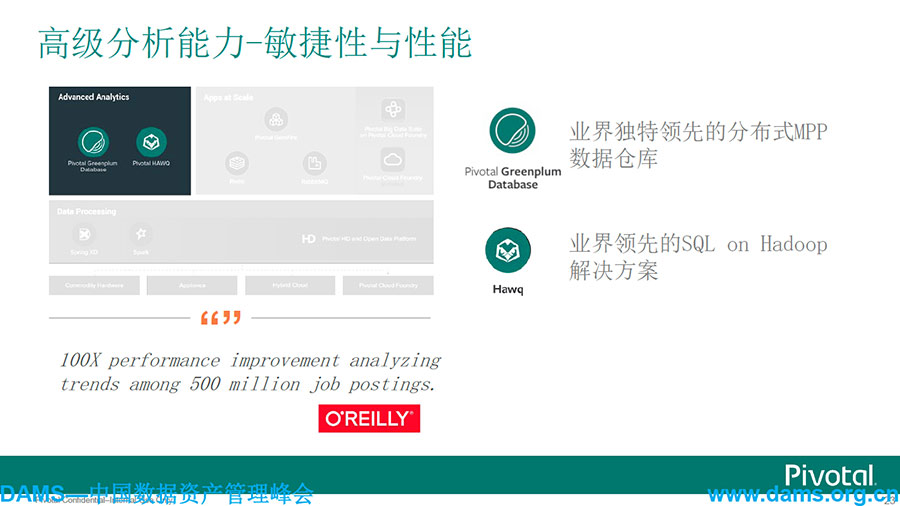
使用深度和智能分析挖掘卓越的商业远见,MPP数据库Greenplum在中国市场是当之无愧的领导者。业界领先的SQL on Hadoop——Hawq,Hawq跟Spark进行测试发现,Hawq基本是完胜Spark的,这也体现了商业版本和开源版本一个非常大的区别。
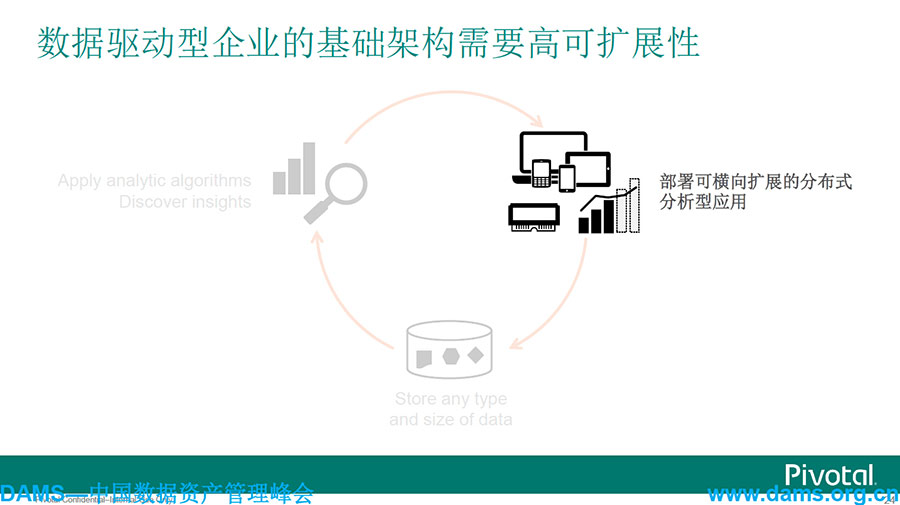

部署可横向扩展的分布式分析型应用,大家应该知道,像GemFire、Redis、RabbitMQ等已经能在这个层面上帮助用户进行弹性的伸缩。

今年,Pivotal推出了新的计划——Open Data的开放,希望未来能与很多企业进行联合,提供最好的产品选择。
(“中国数据资产管理峰会/DAMS 组委会”整理成文,架构师联盟微信号:jiagoushi2015)

扫码关注
获取峰会最新信息

